I am a second-year PhD student in Computer Science at University College London, where I am developing curriculum learning and world model methods that enable embodied agents to learn from synthetic data and generalize to real-world environments. I am co-supervised by Ilija Bogunovic and Jack Parker-Holder, and I am a member of BOLD Lab (formerly UCL DARK Lab) and Rhine AI Lab. I am currently also a Research Scientist Intern at Odyssey, working on world models and agent interaction. Before starting my PhD at UCL, I completed a year-long deep learning research internship at HUAWEI R&D in Cambridge, UK, and hold an MSc in Artificial Intelligence from Leeds University. I have many years of experience in motorsport engineering, but my true passion is in creating machines that can think rather than race.
Publications

The Era of Multi-Agent Imagined Experience
Ahmet H. Güzel
Research Position Report 2026 | Project Page
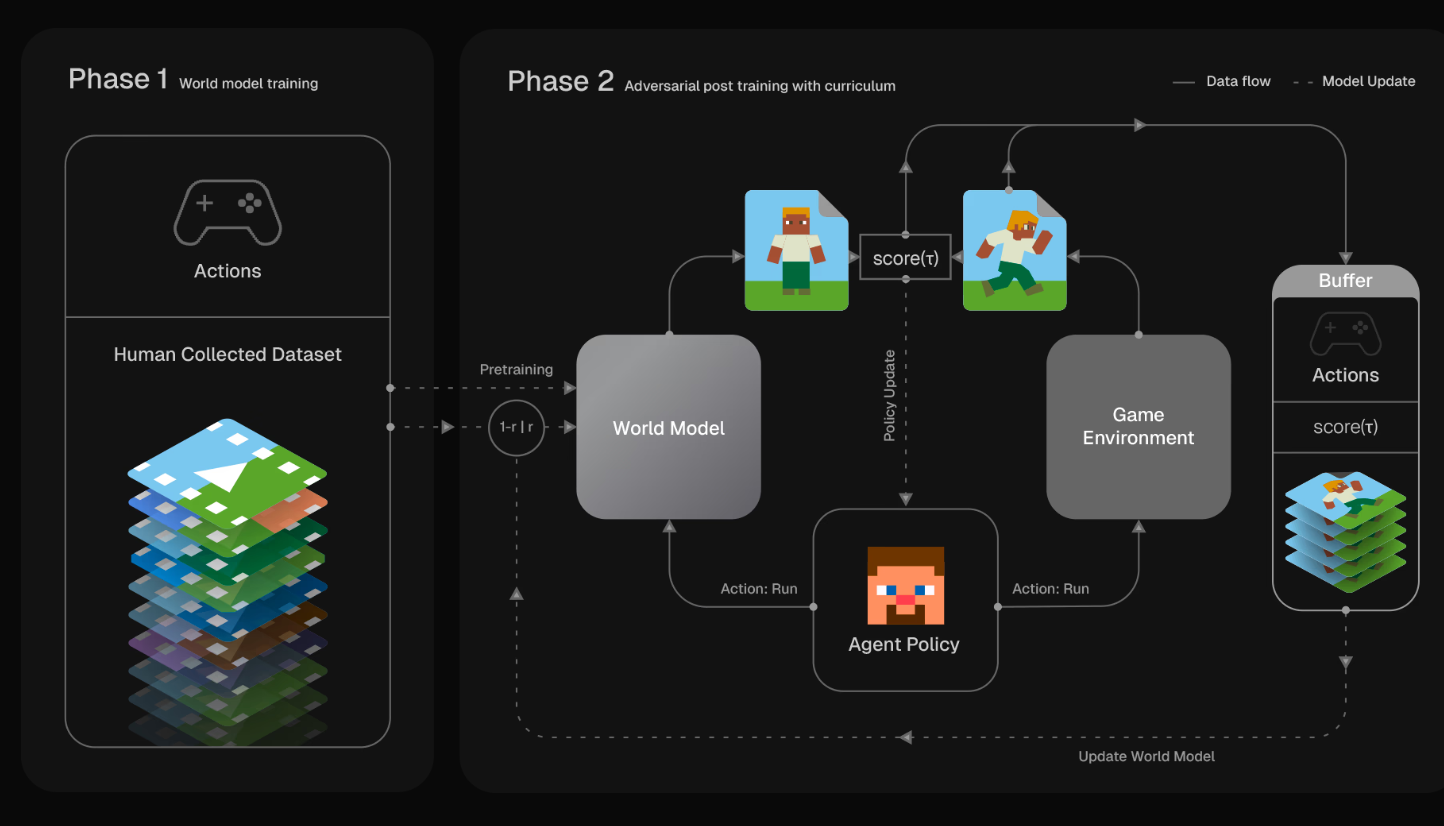
PROWL: Prioritized Regret-Driven Optimization for World Model Learning
, Jenny Seidenschwarz, Benjamin Graham, Jonathan Sadeghi, Jeffrey Hawke, Ilija Bogunovic
Submitted to 2026 NeurIPS | paper | project page
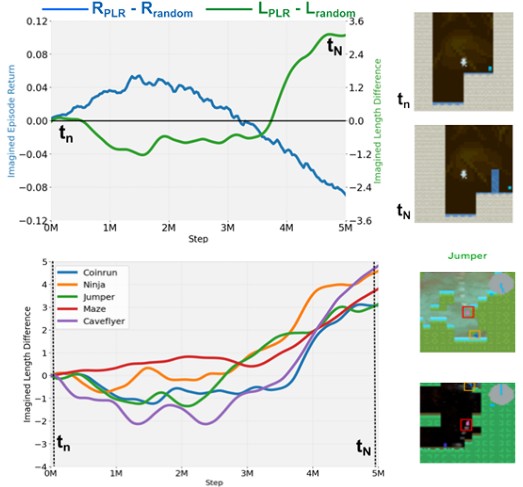
Imagined Autocurricula
, Matthew Thomas Jackson, Jarek Luca Liesen, Tim Rocktäschel, Jakob Nicolaus Foerster, Ilija Bogunovic, Jack Parker-Holder
Accepted 2025 NeurIPS | paper | project page
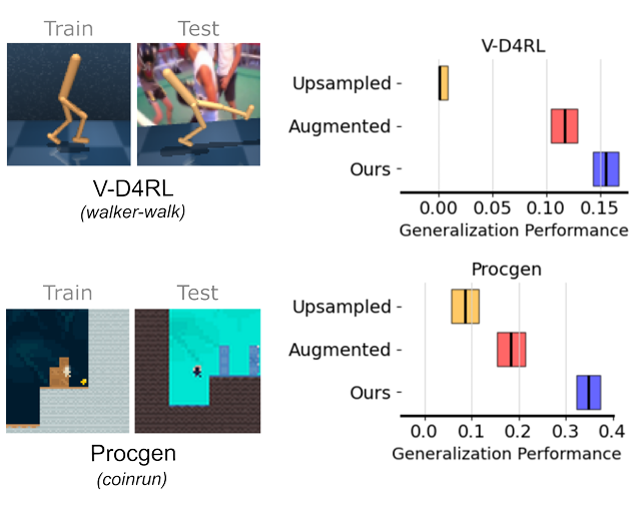
Synthetic Data is Sufficient for Zero-Shot Visual Generalization from Offline Data
, Jack Parker-Holder, Ilija Bogunovic
Accepted 2025 TMLR | paper | 3rd Place Winner - UCL AI CDT Summer Poster Competition 2025

ChromaCorrect: Prescription Correction in Virtual Reality Headsets Through Perceptual Guidance
, Jeanne Beyazian, Praneeth Chakravarthula, Kaan Akşit
Biomedical Optics Express 2023 | paper | code | Best Poster Award

Designing Efficient Image-to-Image Translation Artificial Neural Network Model For Segmenting Fashion Images
, Peihua Lai, Stephan Westland
Intelligent Systems Conference 2024 | code
Research Talks / Presentations
- Imagined Autocurricula: Training Robust Agents with Prioritized World Model Rollouts | 2025 London Summit on Open-Endedness
Teaching Assistant Roles
- 2025/2026 Term 2 | COMP0258: Open-Endedness and General Intelligence
- 2024/2025 Term 2 | COMP0258: Open-Endedness and General Intelligence
- 2024/2025 Term 2 | ELEC0141: Deep Learning for Natural Language Processing
- 2024/2025 Term 1-2 | COMP0016 Systems Engineering lab
- 2024/2025 Term 1 | COMP0213: Object-Oriented Programming for Robotics and AI
UCL Dark Lab MSc Thesis Supervision
- 2024/2025: Selective Inference-Time Planning with World Model Imagination with Labeebah Islam (UCL Machine Learning MSc)
- 2024/2025: Offline Diffusion World Models for Continuous Control Tasks with Adam Vawda-Oomerje (UCL Machine Learning MSc)